| The multi-physics, multi-fidelity simulation requirements of Stanford’s PSAAP center require a modern, massively parallel computational infrastructure. A key component of this infrastructure will be an accurate and efficient reacting compressible flow solver with a RANS (Reynold’s Averaged Navier Stokes) treatment of turbulence. In addition, the infrastructure must support large ensemble simulations involving 1000's of runs, and provide efficient, parallel tools for analyzing the resulting mountain of data. The characterization of turbulence and its interaction with other aspects of our PSAAP problem remains a critical uncertainty, so the infrastructure must also support an LES/DNS solver where turbulence can be largely/completely resolved and these uncertainties reduced. Finally, development efforts must be cognizant of the current trajectory of computer hardware towards highly heterogeneous processors and deep memory hierarchies. |
| |
We are pursuing two approaches to support the Center’s simulation requirements:
- To support current and near-future requirements on existing platforms, a C++/MPI infrastructure called Mum has been developed and is described below.
- For future (or existing non-traditional) architectures, we are developing a domain-specific language (DSL) for mesh-based PDEs called Liszt, also described below.
|
| |
| |
| Liszt |
|
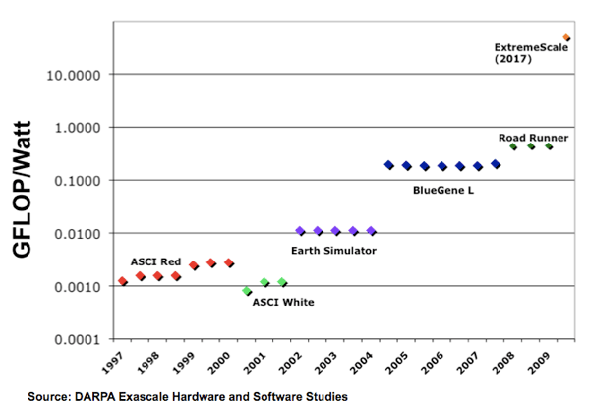
Power efficiency is causing a shift to heterogeneous computer platforms. Future supercomputers will combine features from distributed memory clusters (MPI), Multi-core SMPs (e.g. 32 core, 4-socket systems, Shared memory, Threads/locks, OpenMP), Many-core GPUs (e.g. Fermi, Larrabee, Separate GPU memory, SIMT programming model like CUDA). Examples already exist, including LANL Roadrunner and ORNL Fermi. |
 |
| |
| At present, efficient utilization of this new hardware has required major software rewrites. A critical question is thus: |
| “Is it possible to write one program and run it on all these machines?” |
The Liszt research project is our answer to this question. We believe it is possible using domain-specific languages (DSLs). DSLs exploit domain knowledge to provide the following advantage:
- Productivity: Separate domain expertise (computational science) from computer science expertise
- Portability: Run on wide range of platforms
- Performance: Super-optimize using a combination of domain knowledge and platform knowledge
- Innovation: Allows vendors to change architecture and programming models in revolutionary ways
|
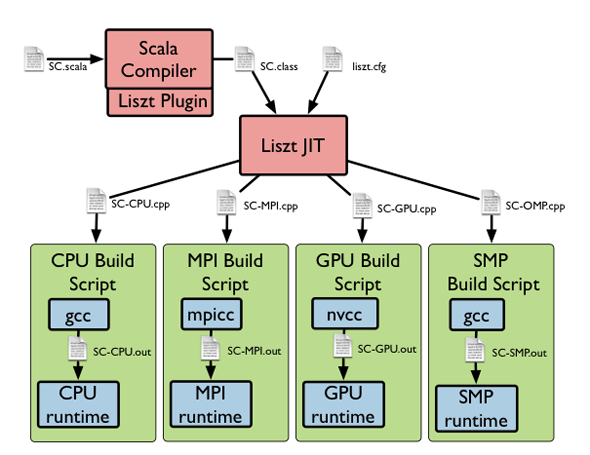
| The Liszt DSL is a domain-specific language for writing mesh-based programs for solving partial differential equations. Liszt code is a proper subset of the syntax and typing rules of the Scala programming language. Currently Liszt programs are written in Scala; a compiler-plugin to the Scala compiler translates the Scala code into an intermediate representation used by the Liszt compiler. |
 |
| |
| |

